
vamchowdary72[at]gmail
Education
-
UCSB
PhD
- Understanding and designing DNN architectures from approximation theoretic perspective, with focus on efficincy and provable generalization.
- Advisor: Prof. Shivkumar Chandrasekaran
-
UCSB
Masters
- Thesis: A study of generalization in deep neural networks
- GPA: 4.0/4.0
-
IIT Roorkee
Bachelors in ECE
- Thesis: Low-cost display devices using nanoparticles
- Advisors: Prof. Brijesh Kumar and Prof. Sanjeev Manhas
- GPA: 8.09/10.0
Experience
-
Cartesia AI
Researcher
-
Amazon AGI
Applied Scientist Intern
- Trained a novel Mixture of Experts (MoE) architecture to reduce inter-node communication costs.
-
Stealth startup
ML Researcher
- Part of the founding team, I led groundwork and architectural setup for ML based solutions, developing Vision, NLP, and speech-based models for tasks in the supply chain industry.
-
Apple
Software Intern
- Developed physics based algorithms to improve the Fall Detection feature. Created data processing pipelines to efficiently handle hundreds of hours of time series data.
-
UCSF
Grad Researcher
- Developed Medviz - an AWS web portal and visualization tool for deploying machine learning models for processing of large PET/MRI datasets.
-
Briteseed
ML Intern
- Trained CNNs on hyperspectral image data from surgical tools to detect tissues.
-
Samsung Research
Engineer
- Music Information Retrieval (MIR).
-
VIOS Medical
Embedded Intern
- Characterized different wireless modules for energy consumption and connectivity.
- Developed software packaging and Linux distribution tools.
I completed my Ph.D. at the University of California, Santa Barbara (UCSB), where I was advised by Shiv Chandrasekaran. I am now a researcher at Cartesia AI.
My dissertation focused on approximation-theoretic approaches to designing neural network architectures that are efficient and have robust generalization. My recent work includes efficient neural network-based solvers for PDEs.
Posts

Learning LU Factorization using gradient descent
December 27, 2025
Formulating LU factorization of linear operators as a neural network training problem by representing L and U as structured weight matrices.
Publications

MNO: A Multi-modal Neural Operator for Parametric Nonlinear BVPs
Vamshi C Madala, N Govindarajan, S Chandrasekaran
AAAI Workshop on AI to Accelerate Science and Engineering (AI2ASE), 2026
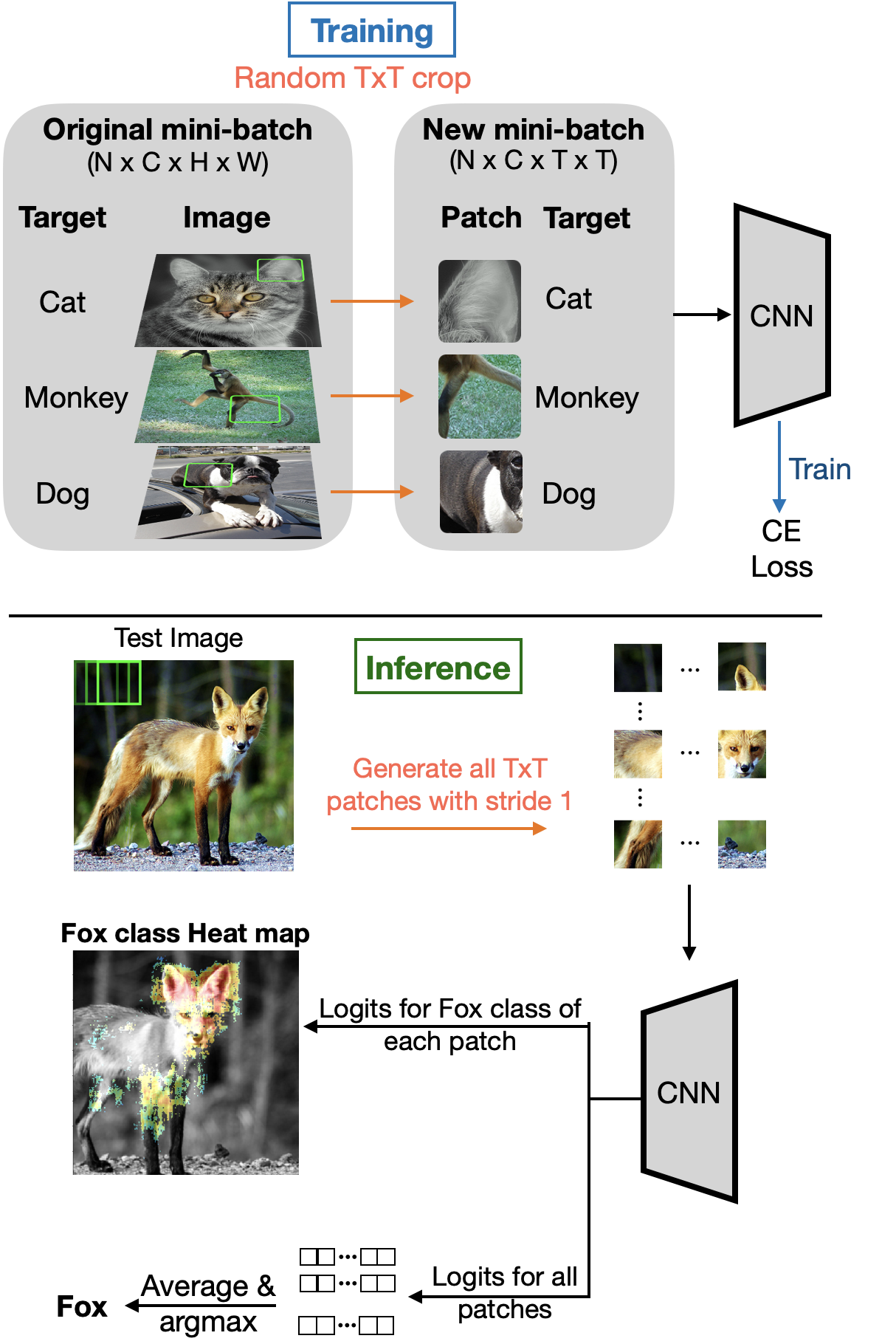
CNNs Avoid the Curse of Dimensionality by Learning on Patches
Vamshi C Madala, S Chandrasekaran, J Bunk
IEEE Open Journal of Signal Processing, vol. 4, pp. 233-241, 2023
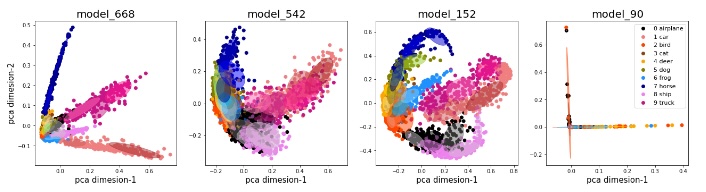
Understanding and Visualizing Generalization in UNets
A Rajagopal, Vamshi C Madala, T.A Hope, P Larson
Proceedings of the Fourth Conference on Medical Imaging with Deep Learning, 2021
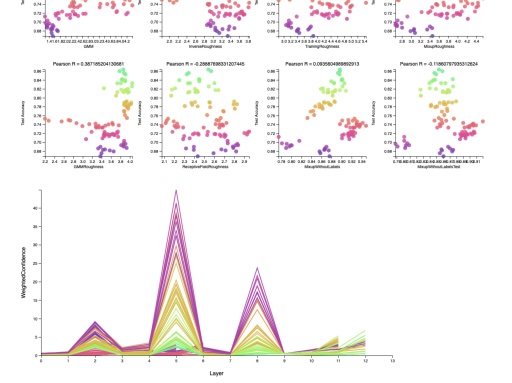
Predicting Generalization in Deep Learning via Local Measures of Distortion
A Rajagopal, Vamshi C Madala, S Chandrasekaran, P Larson
arXiv preprint arXiv:2012.06969, 2020
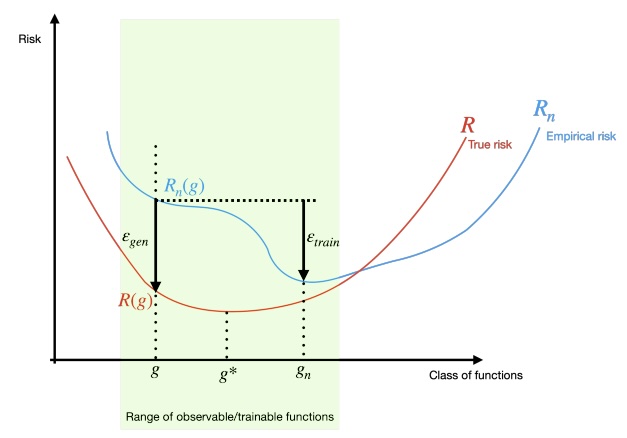
A Study of Generalization in Deep Neural Networks
Vamshi C Madala
Master's Thesis, University of California, Santa Barbara, 2021